简介#
LSM-Tree的全称是 Log-Structured Merge Tree,即“日志结构合并树”。它适用于写入密集型应用,目前所有主流的高写入性能数据库(HBase, Cassandra, RocksDB, LevelDB, InfluxDB, 甚至 MySQL 的 MyRocks 引擎)底层全是LSM-Tree。
为什么需要它#
MySQL InnoDB 默认使用 B+ 树,它的特点是读性能极佳,但随机写入慢,因为插入数据时,可能需要修改磁盘上某个随机位置的页,导致大量的磁盘寻道。LSM-Tree 的核心思想是:把随机写入转变为顺序写入。机械硬盘/SSD的顺序写速度远快于随机写,LSM-Tree 放弃了部分读性能,以换取极高的写入性能。
核心组件#
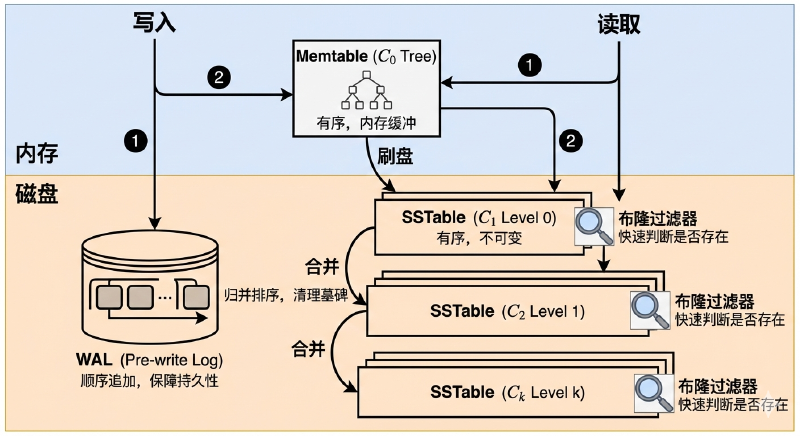
该树有两个关键组件:内存缓冲区(Memtable)和磁盘驻留表(SSTable)。其主要思想是接受对树部分的写入,并定期或者在达到特定大小时将其刷新到磁盘。
预写日志(WAL-Write Ahead Log)#
这是保证实现 ACID 中的D(持久性)的关键,在数据写入内存 Memtable 之前,必须先顺序追加到磁盘上的 Log 文件中。这样即使服务器突然断电,内存中的数据丢失,重启后也能通过重放 WAL 恢复数据。
Memtable(\(C_0\) Tree)#
Memtable 是 LSM-Tree 在内存中的缓冲区,它是一个有序的 Key-Value 存储。当有新的写入时,先写入 Memtable。
SSTable(\(C_1 \sim C_k\) Tree)#
SSTable (Sorted String Table) 是数据在磁盘上的存储格式。它具有以下特性:
- 有序性:内部 KV 按序排列,支持二分查找。
- 不可变性 (Immutable):一旦生成,永不修改。修改=写新值,删除=写墓碑 (Tombstone)。
- 分层结构:原论文提出了 \(C_0, C_1, \dots, C_k\) 的多层级结构。当 \(C_1\) 层太大时,会合并到 \(C_2\) 层,以此类推。越下层的数据越老,容量越大。
运作流程#
- 写入 (Write)
- 先写 WAL:确保数据不丢失(顺序写磁盘,极快)。
- 再写 Memtable:在内存中更新跳表/红黑树。
- 刷盘 (Flush)
- 当 Memtable 达到阈值,冻结为 Immutable Memtable。
- 后台线程将其序列化并顺序写入磁盘第 0 层(Level 0),生成新的 SSTable。
- 此时可以清空对应的 WAL。
- 合并 (Compaction)
- 随着数据写入,SSTable 会越来越多。Compaction 进程会在后台将重叠的 SSTable 进行归并排序。
- 目的:1. 回收空间(物理删除被标记为 Tombstone 的数据);2. 减少读取时需要扫描的文件数量;3. 把数据下沉到更冷的层级。
- 读取 (Read) 与优化
- 查询顺序:Memtable -> Immutable Memtable -> Level 0 SSTable -> Level 1 SSTable …
- 读放大痛点:最坏情况下要查所有文件,速度慢。
- 优化 - 布隆过滤器 (Bloom Filter):为了避免每次都去磁盘查 SSTable,LSM-Tree 会为每个 SSTable 生成一个布隆过滤器(常驻内存)。在查文件前,先问布隆过滤器“这个 Key 可能在这里吗?”。如果回答“不在”,则直接跳过该文件。这样可以极大提升随机读性能。
HFile#
HFile是 HBase 中对于SSTable的实现,也即 HBase 进行数据存储时的实际存储文件。
结构#
HFile由很多个block组成,它们从逻辑上可以分为四个部分:
- Scanned block section: 在 HBase 顺序扫描
HFiles的时候需要被读取的块内容; - Non-scanned block section: 在 HBase 顺序扫描
HFiles的时候不会被读取的块内容,主要包括Meta Block和Intermediate Level Data Index Blocks两部分; - Load-on-open-section: 这部分数据在
region server启动时,需要被加载到BlockCache中。包括FileInfo、Bloom filter block、data block index和meta block index; - Trailer: 这部分主要记录了
HFile的基本信息、各个部分的偏移值和寻址信息。
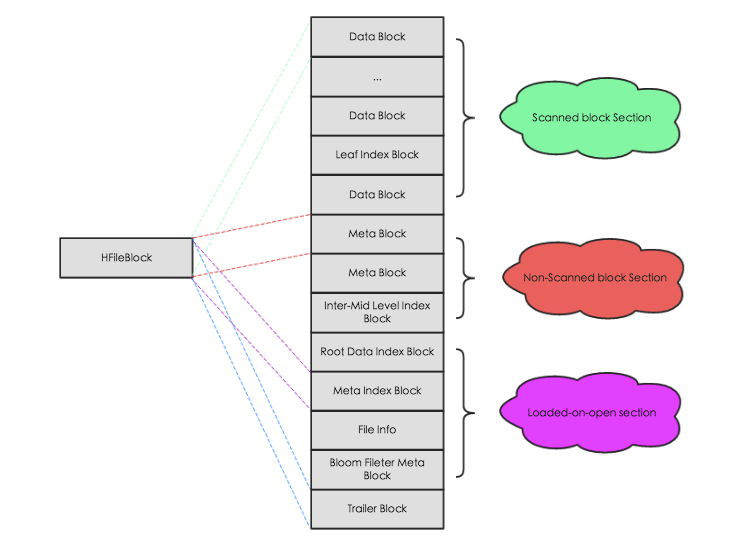
每个block的大小可以在创建表列簇的适合指定,大的block有利于顺序扫描,小的block有利于随机查询。
HBase 中的block又可以分为四种:Data Block,Index Block,Bloom Block和Meta Block。
- Data Block用于存储实际数据,通常情况下每个Data Block可以存放多条KeyValue数据对;
- Index Block和Bloom Block都用于优化随机读的查找路径,其中Index Block通过存储索引数据加快数据查找,而Bloom Block通过一定算法可以过滤掉部分一定不存在待查KeyValue的数据文件,减少不必要的IO操作;
- Meta Block主要存储整个HFile的元数据。
布隆过滤器#
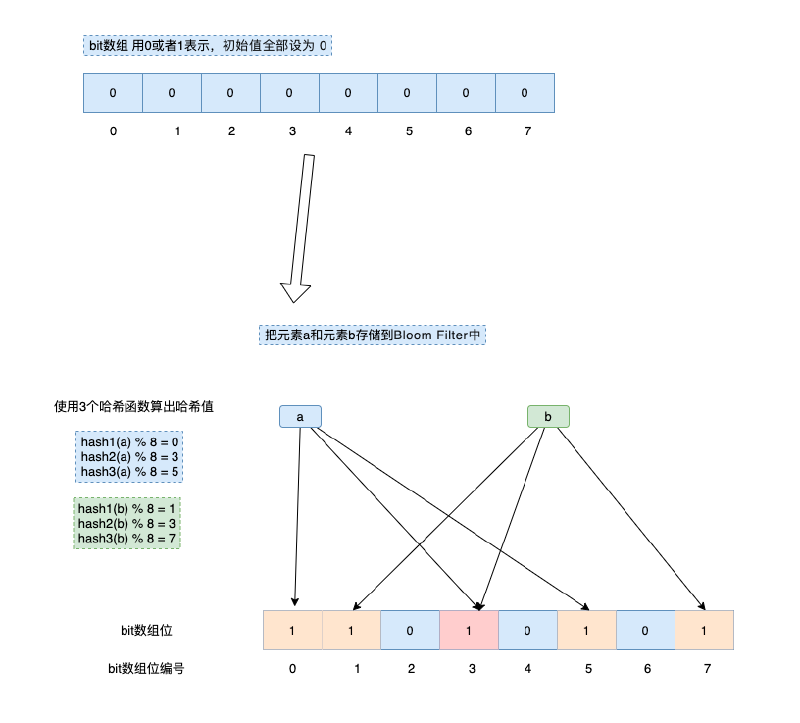
布隆过滤器使用位数组实现过滤,初始状态下为数组的每一位都为0。
- 往里面添加元素时,使用一组不同的哈希函数对元素值计算哈希,可以得到一个整数索引值,该值与数组长度取余后,将对应的索引位置置为1。这一过程中可能存在哈希碰撞。
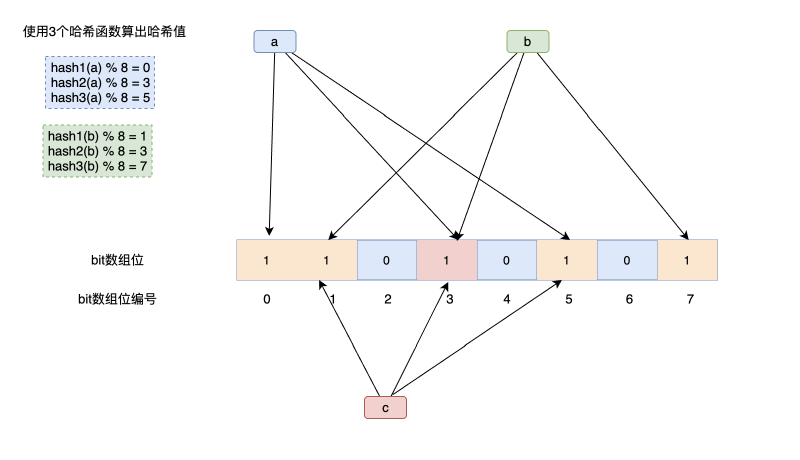
- 检测元素是否存在时,使用与刚才相同的一组哈希函数对元素值计算哈希,得到一组数组位置。只有在这些位置的值都为1的适合才认为元素可能存在,如果其中有一个为0,则说明元素不存在。
- 正常情况下不会进行删除,因为可能导致误删。
参考文献:
