learning.oreilly.com
↗
原文链接
designing-data-intensive-applications
数据密集型应用的一些常见需求
Such applications are typically built from standard building blocks that provide commonly needed functionality. For example, many applications need to:
- Store data so that they, or another application, can find it again later (databases)
- Remember the result of an expensive operation, to speed up reads (caches)
- Allow users to search data by keyword or filter it in various ways (search indexes)
- Handle events and data changes as soon as they occur (stream processing)
- Periodically crunch a large amount of accumulated data (batch processing)
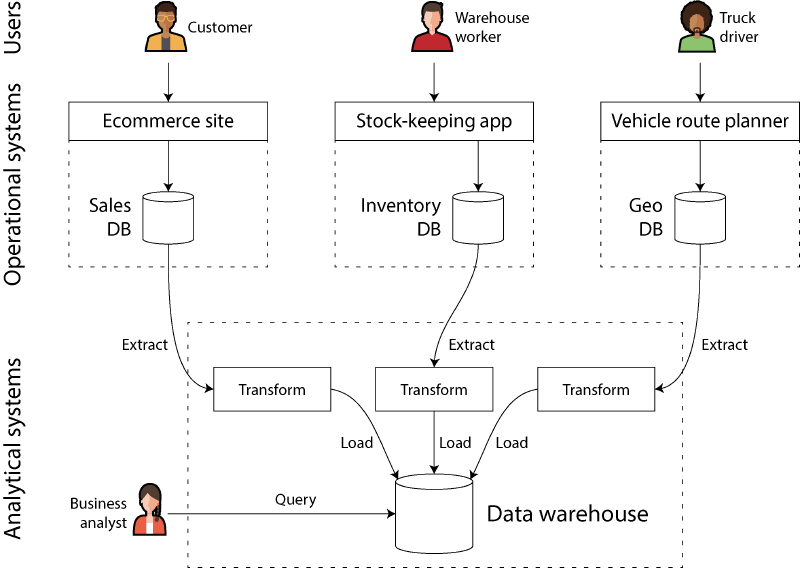
Operational Versus Analytical Systems 运营系统与分析系统#
OLTP vs OLAP:数据处理的分流#
OLTP也即运营系统,OLAP也即分析系统。这两种类型决定了数据库选型和架构设计。
| 特性 | OLTP (联机事务处理) | OLAP (联机分析处理) |
|---|---|---|
| 主要目标 | 支撑业务运行(如下单、支付、评论) | 商业决策与洞察(如报表、趋势预测、ML) |
| 用户 | 终端用户、后端服务(Java应用) | 业务分析师 (BI)、数据科学家 |
| 读写模式 | 点查询 (Point Query),按Key读写,低延迟 | 全表扫描,聚合计算 (Sum, Count),高吞吐 |
| 数据状态 | 当前最新状态 (Current State) | 历史事件流 (History of events) |
| 数据量级 | GB ~ TB | TB ~ PB |
| 典型代表 | MySQL, PostgreSQL, Oracle | Redshift, Snowflake, ClickHouse |
数据基础设施的演进#
为了解决OLTP和OLAP的冲突,架构发生了演变:
- Data Warehouse(数据仓库)
- 目的:将数据从各业务库提取出来,清洗并转换(extract-transform-load, ETL)后存入一个专门的分析数据库。
- 特点:Schema-on-write(写时模式),通常是关系型的,适合SQL和BI报表。
- Data Lake(数据湖)
- 背景:数据科学家需要非结构化数据(文本、图像)或原始数据进行机器学习,SQL不够用了。
- 特点:Schema-on-read(读时模式),存原始文件(如Parquet, Avro),符合"Sushi Principle"(raw data is better)。
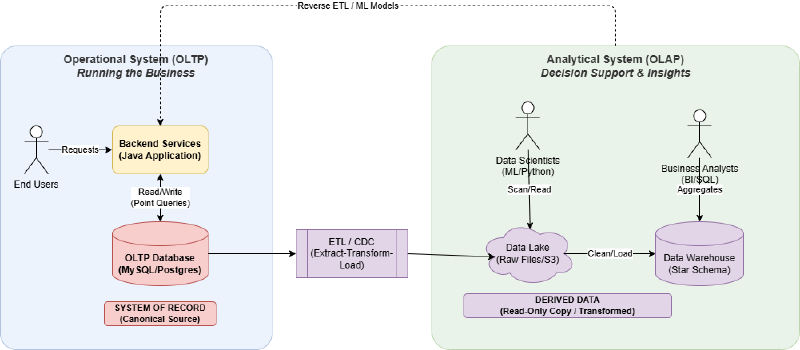
数据流向:记录系统 vs 派生数据#
- System of Record (记录系统):数据的权威版本。如果数据不一致,以此处为准。通常是应用连接的OLTP数据库。
- Derived Data Systems (派生数据系统):通过某种方式从记录系统转换而来的数据。比如搜索索引(Elasticsearch)、缓存(Redis)、数据仓库、机器学习模型。
Cloud Versus Self-Hosting 云部署与自托管#
云服务的权衡#
| 维度 | Self-Hosting (自建/自托管) | Cloud Services (云服务) |
|---|---|---|
| 优势 | 完全控制(可魔改源码、深度调优);排查方便(能看底层日志);成本在负载稳定时更低。 | 速度快(无需采购硬件);弹性伸缩(适合负载波动大的场景);运维外包。 |
| 劣势 | 需要组建昂贵的运维团队;扩容周期长;资源闲置浪费。 | Vendor Lock-in (厂商锁定);黑盒(出问题只能等);数据隐私与合规风险。 |
云原生架构#
| Category 类别 | Self-hosted systems 自托管系统 | Cloud native systems 云原生系统 |
|---|---|---|
| Operational/OLTP 运营/OLTP | MySQL, PostgreSQL, MongoDB | AWS Aurora, Azure SQL DB Hyperscale, Google Cloud Spanner |
| Analytical/OLAP 分析/OLAP | Teradata, ClickHouse, Spark | Snowflake, Google BigQuery, Azure Synapse Analytics |
总体而言,自托管软件倾向于使用通用计算资源:CPU、RAM、文件系统和IP网络。
而云原生服务的关键思想不仅在于使用操作系统管理的计算资源,还在于基于较低级别的云服务来创建更高级别的服务。比如对象存储服务如Amazon S3、Azure Blob存储和Cloudflare R2用于存储大文件。它们提供的API比典型的文件系统更有限(仅基本文件读写),但它们的优势在于隐藏了底层的物理机器;服务会自动将数据分布到多台机器上。许多其他服务反过来又建立在对象存储和其他云服务之上。例如,Snowflake是一个基于云的分析数据库(数据仓库),它依赖于S3进行数据存储
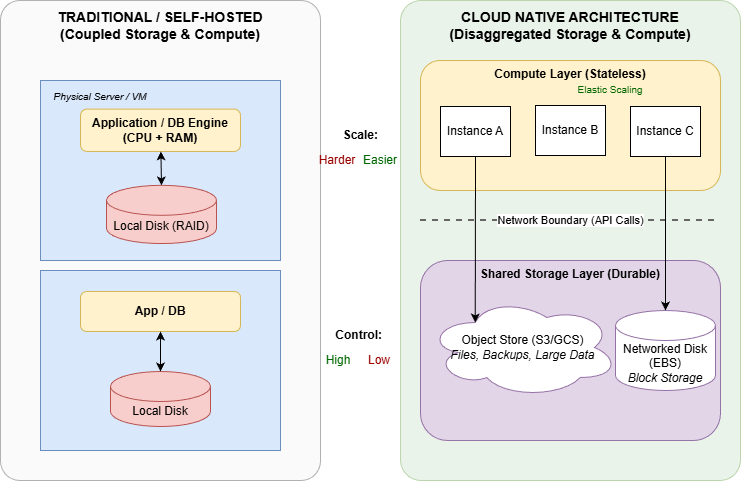
在传统的系统架构中,同一台计算机既负责存储(磁盘)也负责计算(CPU 和 RAM);但在云原生系统中,这两种职责已经有所分离(即存算分离)。
- 计算:是无状态的、临时的(Ephemeral)。如果机器挂了,直接换一台。
- 存储:不再依赖本地硬盘(容易随机器销毁而丢失),而是依赖对象存储(如S3)或网络块存储(如EBS)。
- 优势:利用对象存储的超高可靠性和无限容量,可实现近乎无限的扩展性。