Uber Engineering Blog#
这篇介绍的是Uber的速率限制服务(全局速率限制器GPL),演变成了RLC(速率限制配置器)驱动的全自动控制系统。
在分布式系统设计中,最常用的是分布式计数器存储,通常用Redis实现,每个请求都会递增代表调用方或端点的键值,一旦计数器超过预设阈值,系统便会拒绝请求。
分布式计数器
固定窗口
这是最简单的分布式计数器,Key通常可以设置为prefix:服务名:接口名:时间戳(例如ratelimit:user_login:202310271001)。
- 当请求进来时,执行Redis的
INCR(key)。 - 如果是第一次增加(返回1),设置过期时间。
- 判断返回值是否超过阈值,如果超过,则拒绝。
但这种方法存在边界问题,比如假设限制是“每分钟100次”。如果用户在00:59秒发送了100个请求,又在01:01秒发送了100个请求。虽然两个一分钟周期都没超标,但在00:59到01:01这两秒钟内,系统承受了200次请求。这可能会瞬间打挂数据库。
原子性
在分布式环境下,不能在代码里先读Redis的值,内存里加1再写回,因为会引发竞态条件。可以使用Lua脚本:
| |
滑动窗口
它可以解决前面所说的边界问题。在Redis中,通常通过ZSET实现。
- 每个请求进来时,其
value和score都存当前的时间戳。 - 使用
ZREMRANGEBYSCORE命令,删除“当前时间-窗口长度”之前的旧数据。 - 使用
ZCARD统计剩下的记录数。 - 如果数量小于阈值,则
ZADD加入新请求,否则拒绝。
| |
它的优点在于非常平滑,解决了边界点流量翻倍的问题,但性能开销会大,因为每次都要清理旧数据并计数。
其他
当然,在实际生产中,还有其他方案:
- 令牌桶/漏桶:更平滑,但Redis实现相对复杂。
- 多级限流:同时用固定窗口(粗粒度)和滑动窗口(细粒度)
- 分布式限流:如果QPS极高,可以考虑本地计数器+定期同步
那么这里Uber选择的方案是完全分布式架构,本地代理使用聚合负载而非中央计数器来执行决策。
架构#
GPL引入了三层反馈循环。
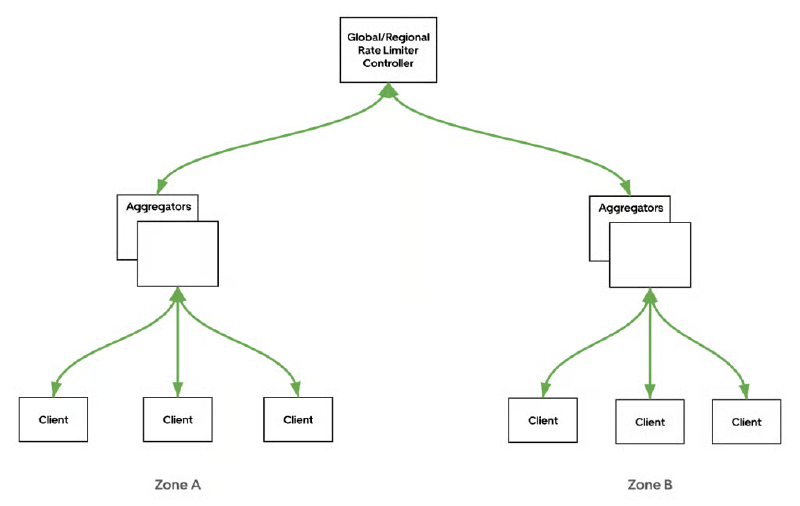
- Rate-limit clients(位于service mesh data面):它根据从聚合器接收的指令,在本地执行每个请求的决策。并每秒向区域级聚合器报告每个主机的请求计数。
- Aggregators(按区域):收集同一区域内所有客户端的指标,计算区域级使用情况,并将其向上发送给控制器。
- Controllers(按区域,全局):聚合区域数据以确定全局利用率,并将更新的丢弃比率指令向下推送回聚合器和客户端。
限流逻辑#
最先使用的是令牌桶算法。每个代理在本地追踪请求数量,并随时间补充令牌,根据可用令牌的数量允许或拒绝请求。
令牌速率是通过比较代理的本地负载与全局限制得出的。代理根据其观察到的流量与全局负载目标之间的比率来计算令牌补充量(按\(\text{rate} \times \text{limit RPS} \)进行补充)。
如果请求到达时有可用令牌,则允许该请求并消耗一个令牌。如果没有可用令牌,则将该请求标记为限流。为了处理突发或不均匀的流量,客户端将未使用的令牌存储在循环缓冲区中,允许在短暂的流量激增期间使用这些令牌。
但这个方案在生产环境中暴露出问题:
- 调用者分配不均(公平性问题):比如全局限流1000RPS,有10个代理实例,系统给每个实例分配了100RPS的额度。实例A接到了500个请求,但它会丢弃400个,实例B接到了10个请求。整体流量才510,但已经开始报错。
- 实例级别的碎片化与突增(扩展性问题):当集群扩展到很大规模,比如全局限流100RPS,1000个实例,每个实例只能分到一个令牌,那突然来一个小波动(比如每秒3个请求)就会触发限流。
虽然后面做了一些改进,但最后他们还是弃用了令牌桶机制,转而使用控制平面驱动的概率丢弃模型。
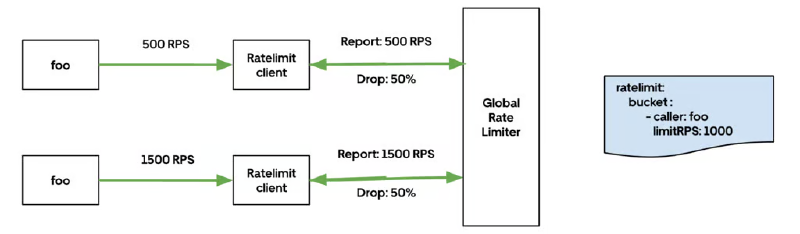
限流执行完全在网络数据平面的客户端层进行。每个代理从控制平面接收速率限制配置和丢弃比例指令。
当请求到达时:
- 客户端会根据配置的存储桶(由调用者、过程或两者共同定义)来匹配请求。
- 如果请求匹配到一个当前具有丢弃比例指令的存储桶,客户端将根据该比例概率性地丢弃一定百分比的请求。
- 如果该存储桶没有活跃的丢弃指令,请求将正常转发。
聚合器和控制器在转发平面之外执行更复杂的计算:它们汇总请求数量,与配置的阈值进行比较,并每秒计算新的丢弃比例,这些更新后的比例会实时推送到所有连接的客户端。
The Cloudflare Blog#
相比HTML,markdown可以大幅减少对于AI的令牌使用量。这篇文章介绍的是他们支持自动将HTML转化成markdown。
