Steve Yegge#
今天的每日阅读从Steve Yegge的博客开始,这位大佬是我今天刚刚知道才关注的,然后就发现他更新博客实在是勤勉,基本上一周一篇甚至更多。
昨晚这篇写的是他对于AI时代软件生存之道理解的。公式理解就是:
$$ \text{Survival}(T) \propto \frac{\text{Savings} \times \text{Usage} \times H}{\text{Awareness\_cost} + \text{Friction\_cost}} $$然后他给出了六个可以用来规划软件生存的杠杆:
- Lever 1: Insight Compression:这个相对开发人员的要求很高,因为它是需要压缩软件行业积累的经验等来形成一个可复用的系统,比如git
- Lever 2: Substrate Efficiency:这种则是为AI提供更高效的工具,而AI重写它的价值不如直接使用,比如grep
- Lever 3: Broad Utility:广泛实用性,也就是一个真正通用的东西,这里他举的例子是Dolt,这是一个融入了
git的版本控制能力的数据库,非常适合AI使用 - Lever 4: Publicity:这个跟传统宣传还有一些区别,因为这里说的认知是对于智能体的认知,工具需要被智能体所了解
- Lever 5: Minimizing Friction:这个也是,针对智能体的售后,智能体需要知道如果出问题应该怎么办,否则它们就会快速切换备用方案
- Lever 6: The Human Coefficient
Uber Engineering Blog#
这篇介绍的是Uber在数据湖规模上升的情况下对Distcp做的一些优化。
Distcp用于以分布式方式在不同位置之间复制大型数据集,它利用Hadoop的MapReduce框架将复制任务并行化和分布到多个节点上,从而实现更快、更具扩展性的数据传输,尤其适用于大规模环境。
Shifting Distcp Preparation Task to AM#
- 瓶颈现象:
- HiveSync Server(提交任务的客户端)上,线程大量阻塞。
- 原因:Distcp在提交任务前,需要在客户端做Copy Listing(列出所有要复制的文件)和 Input Splitting(切分任务)。
- 根本原因:所有线程共用一个 HDFS Client。在高并发下,HDFS Client内部的JVM锁(RPC Locks)成了瓶颈。几百个线程在抢一把锁,导致死锁或剧烈等待。
- 优化方案(Offloading):
- 移交计算:不再由 HiveSync Server(客户端)做这些脏活累活。
- 而是把Copy Listing和Input Splitting移交给YARN Application Master (AM)去做。
- 效果:每个Job都有自己独立的AM容器,相当于把一把全局锁拆成了几千把局部锁,Job提交延迟降低了90%。
Parallelizing Copy Listing Task and Parallelizing Copy Committer task#
- 瓶颈现象:
- Listing慢:对于包含50万文件的目录,Distcp默认是主线程顺序调用
namenode,对大于指定块大小的文件使用getFileBlockLocations API来创建文件分片(块)。当文件状态检查失败时,它还会进行重试。 - Committing慢:复制完后,把临时块改名/合并成正式文件(Commit),也是串行的。
- Listing慢:对于包含50万文件的目录,Distcp默认是主线程顺序调用
- 优化方案:生产者-消费者模型。
- Listing V2:开启多个线程并行去问
namenode,把结果扔进一个Blocking Queue,另一个线程专门负责写结果文件。 - Committing V2:并行做文件拼接(Merge)。
- Listing V2:开启多个线程并行去问
阿里云开发者#
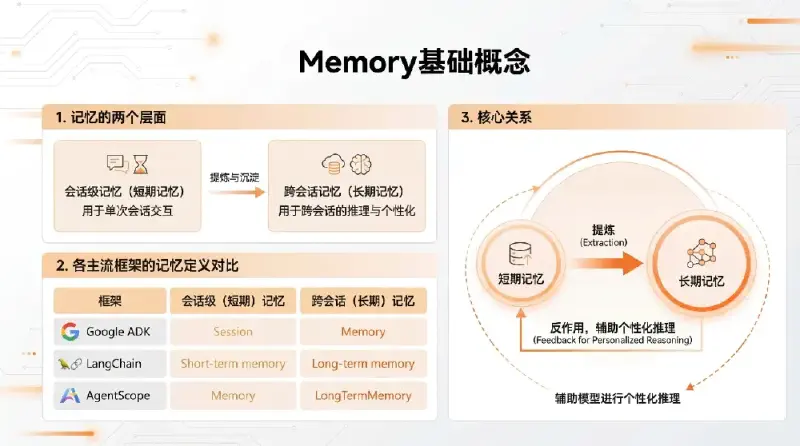
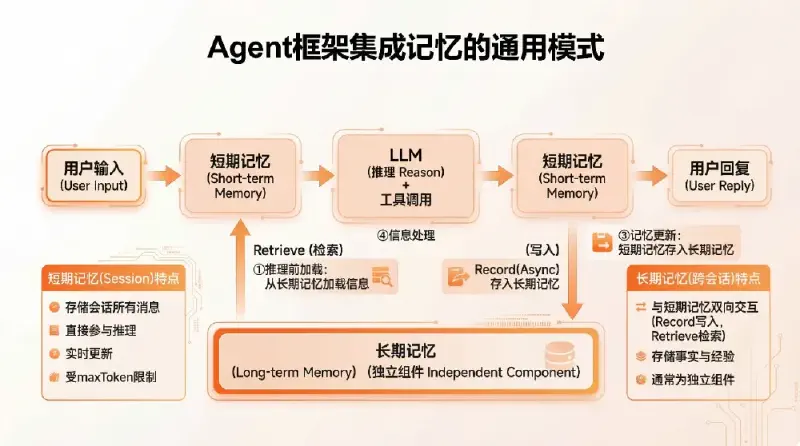
各Agent框架的集成记忆系统通常的通用模式是:
- 推理前加载:根据当前 user-query 从长期记忆中加载相关信息
- 上下文注入:从长期记忆中检索的信息加入当前短期记忆中辅助模型推理
- 记忆更新:短期记忆在推理完成后加入到长期记忆中
- 信息处理:长期记忆模块中结合 LLM+向量化模型进行信息提取和检索
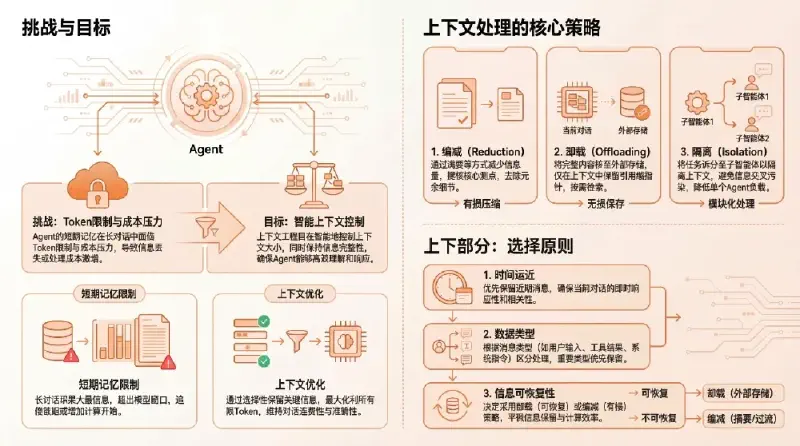
长期记忆涉及到record&retrieve两个流程,需要一些组件:
- LLM大模型:提取短期记忆中的有效信息(记忆的语义理解、抽取、决策和生成);
- Embedder向量化:将文本转换为语义向量,支持相似性计算;
- VectorStore向量数据库:持久化存储记忆向量和元数据,支持高效语义检索;
- GraphStore图数据库:存储实体 - 关系知识图谱,支持复杂关系推理;
- Reranker(重排序器):对初步检索结果按语义相关性重新排序;
- SQLite:记录所有记忆操作的审计日志,支持版本回溯;
| 对比条目 | RAG | 长期记忆 |
|---|---|---|
| 主要目的 | 为大模型提供外部知识,弥补训练数据的局限性(如时效性、专业性) | 为 AI Agent 记录并利用特定用户的历史交互信息,实现个性化、上下文连续的服务 |
| 服务对象 | 全体用户或任务 | 特定用户或会话主体(高度个性化) |
| 知识来源 | 结构化 / 非结构化文档(如 PDF、网页、数据库) | 用户与 Agent 的对话历史、行为日志等 |
小红书技术REDtech#
虚拟线程介绍#
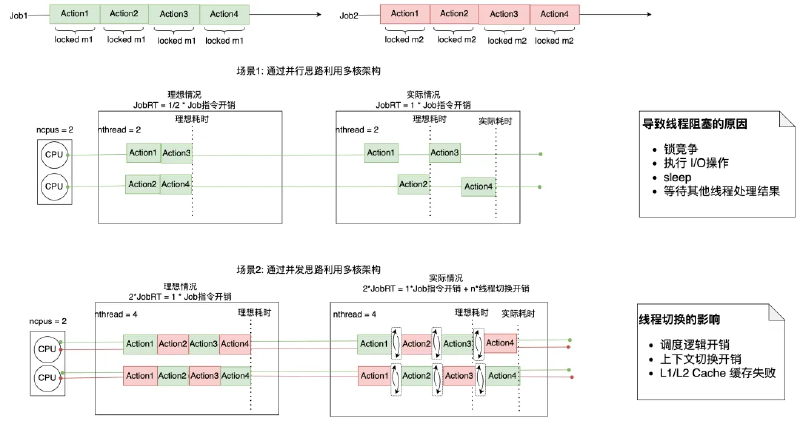
虚拟线程是JDK19中引入的特性,于JDK21生产可用。它是由JVM管理和调度的轻量级线程。传统的Java线程与OS线程一一对应,借助内核的线程管理能力来完成Java线程的调度与管理,因此占用内核线程资源,不可无限扩张;而虚拟线程不占内核线程资源,创建虚拟线程只需要分配少量内存用于放置虚拟线程对象。
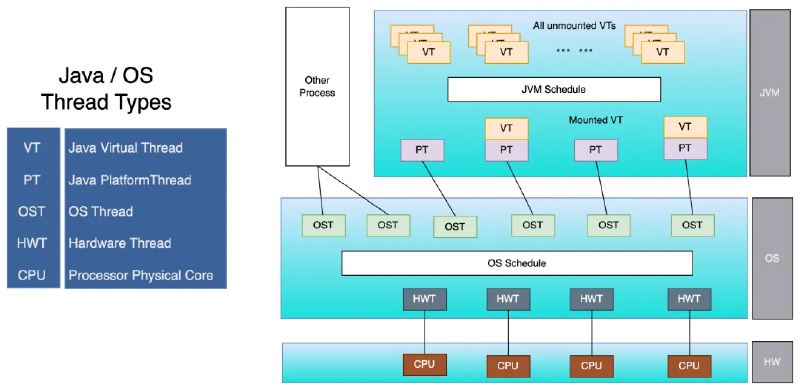
通过这一技术,业务执行逻辑和执行上下文保存在用户层,JVM仅需要预先分配极少量的OS平台线程(CarrierThreads)用来调度执行虚拟线程,它可以轻松支持百万数量级并发。
JVM实现#
JVM会将可执行的虚拟线程(VT)与平台线程(CarrierThreads)绑定,当VT阻塞时与平台线程解绑。应用逻辑上下文全部记录保存在VT,可以按照实际并发需求决定VT的数量。
JVM使用一个虚拟线程专用的FJP(ForkJoinPool)作为虚拟线程调度器,管理n个工作线程(作为 CarrierThreads),n默认对齐CPU核数。每当VT需要进入阻塞状态,则Worker需要将该VT转移到阻塞管理模块,保存好其上下文(如栈帧、寄存器),然后尝试从任务队列获取一个新的任务。CarrierThread优先从本地队列中获取可执行任务,通过WorkStealing机制保障负载均衡。
ForkJoinPool
ForkJoinPool是Java里专门为“可拆分的大任务”设计的并行线程池,典型用法是:将一个大任务拆分成很多小任务(Fork),并行执行,然后再把结果合并(Join)。
其中还有一个WorkStealing机制,即任务窃取。每个线程都有一个双端队列,自己产生的任务自己优先执行(LIFO),空闲线程则会从别的线程队列尾部偷任务(FIFO)。
| 对比维度 | 传统 ForkJoinPool | 虚拟线程 ForkJoinPool(Virtual FJP) |
|---|---|---|
| 任务获取策略 | 面向分治任务,采用后进先出(LIFO),有利于缓存局部性 | 需要保证任务执行的公平性,采用先进先出(FIFO) |
| 阻塞处理方式 | 遇到阻塞操作时,工作线程直接挂起 | 遇到阻塞时,将虚拟线程卸载(unmount),CarrierThread继续执行其他可运行的虚拟线程 |
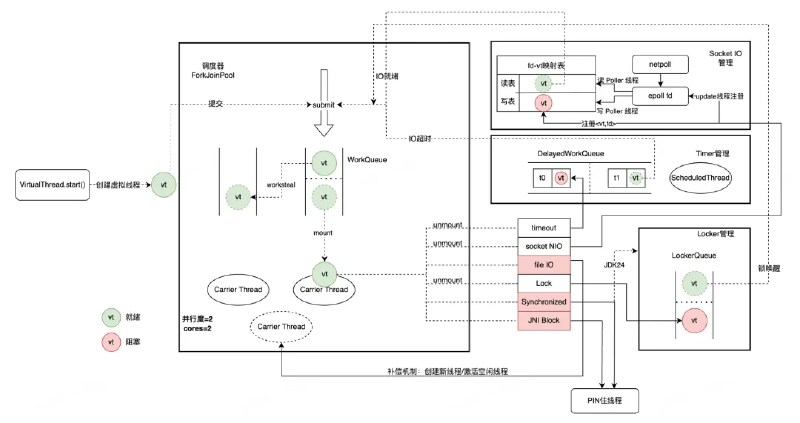
而当CarrierThread挂载执行的VT需要进入阻塞状态时,它会及时卸载(unmount)准备进入阻塞状态的VT,并挂载(mount)另一个可运行的VT;被卸载的VT通过阻塞管理模块管理,当阻塞管理模块探查到VT从可以继续运行,则通过submit操作将其塞回就绪队列。当然,卸载与挂载的过程都需要妥善保管(freeze)和恢复(thaw)VT执行上下文。
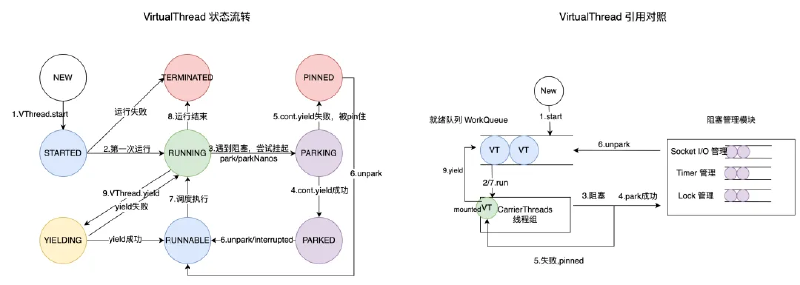
为了避免CarrierThread陷入阻塞,JVM需要在阻塞行为之前hook住VT的执行,并完成卸载、补偿等操作。它会枚举所有VT的阻塞点,在阻塞点中加入卸载代码:
- Socket I/O 操作:卸载VT,将
<VT, fd>映射关系存入表中,通过异步Poller线程轮询管理 - 文件 I/O 操作:VT即将陷入磁盘读写状态(
pinned),额外申请一个CarrierThread补偿算力损失 - JUC锁:卸载VT,VT在锁队列中排队,等锁owner释放后会Notify下一个线程/虚拟线程
- Synchronized:轻量级锁会CAS获取(无阻塞),ObjectMonitor下会陷入阻塞(pinned)
- Native代码阻塞:直接陷入阻塞(pinned),无法处理
RedJDK21#
主要看一下解决synchronized阻塞的方案。
在64位架构的对象头中,Mark word在不同锁状态下用于存储不同信息。

| 状态 | Mark Word 存什么 |
|---|---|
| 无锁 | hash / GC bits |
| 轻量级锁 | 指向栈上BasicLock的地址 |
| 重量级锁 | 指向ObjectMonitor的指针 |
传统Java轻量级锁基于“物理线程+固定栈地址”的设计,加锁时生成BasicLock并存储在栈上,在锁对象MarkWord中直接存储BasicLock在栈上的内存地址;但由于虚拟线程会在CarrierThreads以及堆(unmount时)之间调度切换,“固定的栈上地址”无法准确表达BasicLock实际位置。
那么这里的解决方案是Lightweight_Lock机制,其锁状态存储存储在LockStack中,与栈地址空间解绑,并且会随VT一起unmount和remount。
另外重量级锁还新加了一个UseObjectMonitorTable模式,对象头不再需要存储指向Monitor的指针,而是通过一个全局表存储锁对象与Monitor对象的映射。Monitor中存放实际Owner的线程或虚拟线程ID,这样就可以准确识别是VT还是其挂载的CarrierThread。
