Uber Engineering Blog#
Uber 对于下面这些问题:
- 可变数据模型
- 高更新率的大容量数据流
- 端到端的增量处理以避免全表重新计算
它们选择的是 Apache Hudi™ ,开发了一种专为数据湖设计的新型存储引擎,不过它们的做法是把数据湖与数据库的一些特性做了结合:
- ACID 事务。确保在并发、重试、延迟数据或重叠管道的情况下仍能保持正确性。
- 索引与快速更新。实现跨数百个分区和数十亿条记录高效更新行。
- 增量处理。允许管道仅读取自上次提交以来的变更数据,而非每次扫描数 TB 的数据。
数据湖
数据湖是一种用于集中存储海量数据的架构/平台,它提供了一个统一的存储层,用于存储和管理来自不同来源的数据,包括结构化数据、半结构化数据和非结构化数据。常见的数据湖三层架构包括:Raw Layer(原始数据存储层)、Processed/Clean Layer(处理层)、Curated/Serving Layer(服务层)。
另外,文章还提到:
Uber has been steadily shifting a portion of ingestion from Spark-based batch jobs to Flink®-native streaming to support sub-15-minute freshness SLOs.
Uber 一直在稳步将部分数据摄取从基于 Spark 的批处理作业转向 Flink®原生流处理,以支持低于 15 分钟新鲜度的服务级别目标。
Uber的数据湖技术栈#

Ingestion Layer 数据摄取层#
Spark 批量摄取,用于大规模、每小时或每日的数据管道,处理数据回填、重新处理和高吞吐量的批量写入。
Flink 流式摄取,用于持续、低延迟写入的需求。
Query Layer 查询层#
查询层使用 Spark 和 Presto ,Spark 用于复杂的数据工程和机器学习工作流,Presto 用于高并发交互式分析。
Observability and Monitoring 可观测性和监控#
这里使用的是 Prometheus 和 Grafana。
创新突破#
Metadata Table#
元数据表MDT被用来在极端规模下解决文件列表问题。这实际上是用数据库思维来解决文件系统的瓶颈。
传统的大数据处理直接依赖文件系统(HDFS/S3)的API,但当数量达到一定级别,list操作的 \(O(N)\) 复杂度也会变得不可接收。Uber 引入MDT,实际上是引入LSM-Tree(HFile)结构来索引文件元数据,即在文件系统上构建了一层轻量级数据库索引。
MDT 是一个由 Hudi 管理的键值存储,底层采用HFile(一种基于 Sort String Table SSTable的格式,用于元数据的快速索引),它追踪数据操作所需的所有元数据,例如文件列表、列统计信息(每个 Parquet 文件的最小/最大值)和布隆过滤器。通过将这些元数据原生存储在 Hudi 内部,MDT在许多操作中完全避免了访问文件系统。作为一个键值存储,MDT允许在大规模下实现 \(O(1)\) 的键查找。因此,诸如列出大型文件夹之类的操作可以通过查找与待列出目录对应的特定键,在 \(O(1)\) 时间内完成。
关于SSTable相关知识的介绍可以看下面这篇:
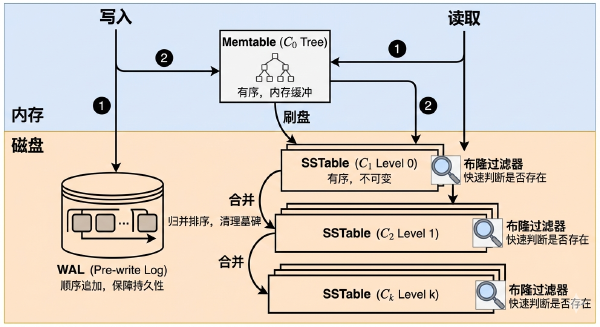
这里我一开始想到 Linux 自己会有inode这种东西来维护元数据,所以比较疑惑为什么要再引入一个MDT。但是 HDFS 或者对象存储的云平台跟它的底层还是有较大的不同。
AWS S3 以及阿里云 OSS 它们的本质都是一个 Key-Value 数据库,它没有真正的inode,也没有目录树结构,所谓的路径对它来说都是一个长字符串,当执行list操作时,它必须扫描所有 Key,然后通过字符串前缀匹配来返回结果。
HDFS 虽然有类似inode的东西,存储在主节点NameNode的内存里,但是NameNode是单点,如果多个Executor同时请求就会瞬间卡死。
HDFS、OSS/S3/GCS
HDFS 是 Hadoop 生态里的分布式文件系统,其他三个都是对象存储。OSS是阿里云对象存储服务,S3是亚马逊对象存储服务,GCS是谷歌对象存储服务。
Record Index#
记录索引用于解决大规模数据场景下的更新插入问题。
记录索引基于HFile的数据结构,存储在元数据表中。它把记录键映射到文件组,无需依赖 HBase 等外部服务器即可实现 \(O(1)\) 复杂度的键值查找。
这里就会涉及到 写放大 vs 读延迟 的问题,在这么大的数据量下维护一个全局索引的写入成本是巨大的,每次写入都要更新索引,但 Uber 愿意这样的原因在于它们的更新频率极高,如果没有索引,合并数据的读代价更无法接受。这也就是典型的空间换时间,以写入性能换取读取/合并性能的权衡。
字节跳动技术团队#
核心痛点#
在微服务架构中,为了计算准确的 R.E.D 指标 (Rate, Errors, Duration),理论上需要全量数据。但为了省钱,通常使用 头采样 (Head-based),即请求一开始就按概率扔掉数据。这导致了很多偶发的“慢请求”和“错误现场”被误删,排查问题时极其痛苦。
架构方案:尾采样 (Tail-based)#
核心思想:先收集、后决策。它会等待一条 Trace 上的所有(或绝大部分)Span 都生成完毕,然后基于完整的链路信息,例如是否包含错误、总耗时是否超标、是否命中了特定的业务标签等,来做出采样决策。

关键技术点:
- 一致性哈希路由:由于 Span 散落在不同机器,通过
hash(TraceId)将属于同一请求的所有片段转发到同一个 Collector 节点,实现“数据聚合”。 - 计算存储分离:使用
SpanToMetrics组件,基于全量流数据实时计算监控指标(保证大盘准确),但只对明细数据(Trace)进行采样存储(节省磁盘)。

这也是一种典型的 “空间换质量” 的设计。通过在 Collector 层消耗更多的内存(缓存未完成的链路)和 CPU(做哈希转发),换取高数据价值密度(即存下来的都是有问题的)。
